A overlooked warning: Causation with out correlation
Usually individuals who perform multivariate statistical analyses on info are unaware of particular restrictions. Many moments this is owing to absence of familiarity with statistical checks. One warning we do see a lot even though is: Correlation does not suggest causation. This is, of course, definitely correct. If you consider my excess weight from 1 to twenty many years of age, and the price tag of gasoline in the US for the duration of that period, you will uncover that they are extremely correlated. But typical feeling tells me that there is no causation by any means amongst these two variables.
So correlation does not indicate causation alright, but there is an additional warning that is seldom observed: There can be strong causation with no any correlation. Of course this can guide to even more bizarre conclusions than the “correlation does not imply causation” difficulty. If there is sturdy causation amongst variables B and Y, and it is not demonstrating as a correlation, yet another variable A could “jump in” and “steal” that “unused correlation” so to talk.
The chain smokers “study”
To illustrate this stage, let us take into account the following fictitious case, a research of “100 cities”. The study focuses on the result of using tobacco and genes on lung cancer mortality. Smoking cigarettes substantially will increase the probabilities of dying from lung most cancers it is a really robust causative aspect. Right here are a number of much more specifics. Among 35 and forty % of the population are chain smokers. And there is a genotype (a set of genes), identified in a tiny percentage of the populace (all around seven per cent), which is protective against lung cancer. All of those who are chain smokers die from lung cancer unless of course they die from other causes (e.g., mishaps). Dying from other causes is a lot more typical between individuals who have the protective genotype.
(I developed this fictitious knowledge with these associations in head, making use of equations. I also extra uncorrelated mistake into the equations, to make the data appear a little bit far more practical. For illustration, random deaths transpiring early in life would reduce marginally any numeric association among chain smoking cigarettes and cancer fatalities in the sample of a hundred metropolitan areas.)
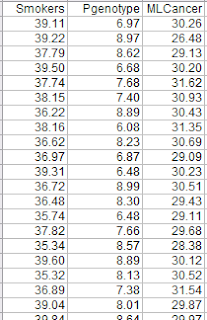
The table under displays portion of the information, and presents an notion of the distribution of proportion of people who smoke (People who smoke), share with the protective genotype (Pgenotype), and percentage of lung most cancers deaths (MLCancer). (Click on on it to enlarge. Use the "CRTL" and "+" keys to zoom in, and CRTL" and "-" to zoom out.) Every single row corresponds to a metropolis. The relaxation of the data, up to row a hundred, has a similar distribution.
The graphs under show the distribution of lung most cancers fatalities from: (a) the proportion of people who smoke, at the top and (b) the percentage with the protective genotype, at the bottom. Correlations are demonstrated at the best of each and every graph. (They can range from -one to 1. The nearer they are to -1 or 1, the much better is the affiliation, unfavorable or constructive, between the variables.) The correlation among lung most cancers fatalities and percentage of people who smoke is a bit negative and statistically insignificant (-.087). The correlation amongst lung most cancers fatalities and proportion with the protective genotype is negative, robust, and statistically substantial (-.613).
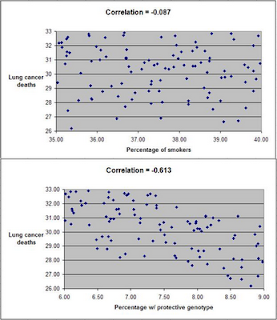
Even although smoking considerably boosts the odds of dying from lung most cancers, the correlations notify us or else. The correlations notify us that lung most cancers does not seem to cause lung cancer fatalities, and that obtaining the protective genotype would seem to substantially reduce cancer deaths. Why?
If there is no variation, there is no correlation
The reason is that the “researchers” gathered info only about chain smokers. That is, the variable “Smokers” contains only chain people who smoke. If this was not a fictitious situation, focusing the research on chain people who smoke could be seen as a clever method used by researchers funded by tobacco firms. The researchers could say something like this: “We targeted our examination on people most probably to produce lung cancer.” Or, this could have been the end result of simple stupidity when creating the analysis venture.
By limiting their review to chain people who smoke the scientists drastically diminished the variability in one specific variable: the extent to which the examine individuals smoked. Without having variation, there can be no correlation. No issue what statistical check or computer software is used, no substantial affiliation will be discovered amongst lung most cancers deaths and percentage of people who smoke dependent on this dataset. No subject what statistical check or computer software is employed, a substantial and sturdy affiliation will be located in between lung cancer fatalities and proportion with the protective genotype.
Of system, this could lead to a very deceptive conclusion. Smoking cigarettes does not trigger lung cancer the real lead to is genetic.
A be aware about diet program
Consider the analogy amongst smoking cigarettes and usage of a specific foods, and you will almost certainly see what this indicates for the analysis of observational data relating to nutritional alternatives and condition. This applies to nearly any observational review, like the China Research. (Research employing experimental manage manipulations would presumably guarantee ample variation in the variables studied.) In the China Research, information from dozens of counties had been gathered. A single could discover a important association among usage of foodstuff A and disease Y.
There may possibly be a significantly more powerful affiliation amongst meals B and condition Y, but that affiliation may possibly not demonstrate up in statistical analyses at all, just due to the fact there is little variation in the information regarding use of foods B. For case in point, all people sampled may possibly have eaten meals B about the exact same quantity. Or none. Or somewhere in between, in a fairly little range of variation.
Statistical illiteracy, bad choices, and taxation
Stats is a “necessary evil”. It is valuable to go from modest samples to huge ones when we study any possible causal affiliation. By carrying out so, one particular can uncover out no matter whether an observed result really applies to a bigger percentage of the populace, or is actually restricted to a modest group of people. The issue is that we humans are very negative at inferring real associations from merely hunting at massive tables with numbers. We require statistical exams for that.
However, ignorance about fundamental statistical phenomena, this kind of as the 1 described listed here, can be pricey. A group of people might get rid of foodstuff A from their diet regime dependent on coefficients of association resulting from what seem to be very intelligent analyses, changing it with food B. The difficulty is that foods B may be similarly hazardous, or even a lot more damaging. And, that result could not display up on statistical analyses unless they have sufficient variation in the intake of meals B.
Readers of this weblog may ponder why we explicitly use terms like “suggests” when we refer to a partnership that is advised by a important coefficient of association (e.g., a linear correlation). This is why, between other motives.
One particular does not have to be a mathematician to recognize standard statistical concepts. And carrying out so can be really useful in one’s existence in common, not only in diet program and life style selections. Even in easy options, these kinds of as what to be on. We are often betting on anything. For illustration, any expense is in essence a guess. Some results are considerably far more probable than others.
As soon as I experienced an exciting dialogue with a higher-level officer of a condition federal government. I was element of a consulting team functioning on an details engineering task. We were speaking about the point out lottery, which was a huge resource of income for the state, evaluating it with state taxes. He advised me something to this influence:
Our lottery is basically a tax on the statistically illiterate.
Title: Strong causation can exist without any correlation: The strange case of
the chain smokers, and a note about diet
Rating: 910109 user reviews.
Rating: 910109 user reviews.
Posted by:
Admin Updated at: 4:50 PM
No comments:
Post a Comment